文章目录[隐藏]
- 一、时间序列概念
- 二、时间序列异常检测
- 三、时序类型
- 四、异常类型
- 五、重要概念
- 六、数据平滑
- 七、异常检测分析步骤
- 八、异常检测方法
- 九、资源 Useful links
- 十、后记
- 参考
- 异常检测主要方法总结
- 安全防护-笔记-待完善
- 微信小程序开发实战9_3 小程序URL Scheme
- CMake – 概览
- MacOS使用Nvim+LaTeX+Skim配置高效的论文写作环境
- 阿里云容器服务-kubermetes集群无操作权限
- 1.3.5 手写数字识别之资源配置
- 【云原生之Docker实战】使用Docker部署image2df工具
- 《变量4》读书笔记
- 【PyTorch深度学习项目实战100例】—— 基于Transformer实现100项体育运动分类 | 第48例
- Java 进阶(15)线程安全集合
- HR:面试官最爱问的linux问题,看看你能答对多少
- vscode开发常用的工具栏选项,查看源码技巧以及【vscode常用的快捷键】
- 数据要素化条件之一:原始性
- 【面试题 高逼格利用 类实现加法】编写代码, 实现多线程数组求和.
- 一个python训练
- Mybatis03学习笔记
- 设置或取得c# NumericUpDown 编辑框值的方法,(注意:不是Value值)
- 使用NPOI 技术 的SetColumnWidth 精确控制列宽不能成功的解决办法(C#)
- Mysql 数据库zip版安装时basedir datadir 路径设置问题,避免转义符的影响
最近对预测及异常检测进行了一些研究和学习,把所学东西做一个汇总整理。欢迎交流拍砖 👏(侵权删)
目录
一、时间序列概念
二、时间序列异常检测
三、时序类型
四、异常类型
4.1 点异常
4.2 上下文异常
4.3 集合异常
五、重要概念
5.1 平稳性
5.2 趋势
5.3 季节性
5.4 周期性
5.5 自相关
5.6 白噪声
5.7 虚假相关性
六、数据平滑
6.1 moving average
6.2 cumulative moving average
6.3 Weighted moving averaging
6.4 Exponential smoothing
6.5 Holt exponential smoothing
6.6 Holt-Winters exponential smoothing
七、异常检测分析步骤
八、异常检测方法
8.1 概率与统计模型
8.1.1 极值分析(箱型图)
8.1.2 统计假设检验(3σ准则)
8.1.3 时间序列建模(移动平均、指数平滑、ARMA、ARIMA)
8.2 基于相似度衡量的模型
8.2.1 基于距离度量-KNN
8.2.2 基于聚类
8.3 集成异常检测与模型融合
8.3.1 孤立森林
8.3.2 深度学习
九、资源 Useful links
十、后记
参考
一、时间序列概念
时间序列 (time series,TS) 是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如 1s,1min,1h,1d),因此时间序列亦可作为离散时间数据进行分析处理。
二、时间序列异常检测
时间序列异常检测(TS anomaly detection)的主要目标是从时间序列中识别异常的事件或行为,异常检测算法目前广泛应用于众多领域中,例如量化交易,网络入侵检测,智能运维等。
与之相关的研究领域:
- 时间序列预测(TS Forcasting):目前有众多基于预测思想的时间序列异常检测算法,主要可以产生序列的基带。
- 离群点检测 (Outlier detection) :算法模型同样适用于时间序列异常检测。
三、时序类型
在实际场景中,不同的业务通常会对应不同类型的时间序列模式,一般可以划分为几种类型:趋势性、周期性、随机性、综合性。如下图所示:

因此在实际场景中,难以使用单一模型来学习不同类型时间序列的特征模式,一般使用集成模型或者多个模型同时对时间序列进行异常判断。
四、异常类型
首先需要定义异常:在时间序列中,异常是指在一个或多个信号的模式发生意料之外的变化。主要可以分为以下三类异常。
4.1 点异常
即某些点与全局大多数点都不一样,如下图所示

4.2 上下文异常
即某个时间点的表现与前后时间段内存在较大的差异,如下图所示

时间序列的异常检测问题通常表示为相对于某些标准信号或常见信号的离群点。虽然有很多的异常类型,但是我们只关注业务角度中最重要的类型,比如意外的峰值、下降、趋势变化以及等级转换(level shifts)。
常见的异常有如下几种:
- 革新性异常:innovational outlier (IO),造成离群点干扰不仅作用于X(T),而且影响T时刻以后序列的所有观察值。
- 附加性异常:additive outlier (AO),造成这种离群点的干扰,只影响该干扰发生的那一个时刻T上的序列值,而不影响该时刻以后的序列值。
- 暂时变更异常temporary change (TC):造成这种离群点的干扰是在T时刻干扰发生时具有一定初始效应,以后随时间根据衰减因子的大小呈指数衰减。
- 水平移位异常:level shift (LS),造成这种离群点的干扰是在某一时刻T,系统的结构发生了变化,并持续影响T时刻以后的所有行为,在数列上往往表现出T时刻前后的序列均值发生水平位移。
结合图片来看一下:

4.3 集合异常
即个体不存在异常,但是个体同时出现表现出异常状态,如下图所示

五、重要概念
5.1 平稳性
通常来说,平稳的时间序列指的是这个时间序列在一段时间内具有稳定的统计值,如均值,方差。许多时间序列的统计学模型都是依赖于时间序列是平稳的这一前提条件。
常用平稳性验证方法包括 Augmented Dickey Fuller Test (ADF Test),Kwiatkowski-Phillips-Schmidt-Shin Test (KPSS Test)。
对于非平稳的时间序列,可以通过差分、log 变换或平方根变换转化为平稳序列。
5.2 趋势
当一个时间序列数据长期增长或者长期下降时,表示该序列有趋势 。在某些场合,趋势代表着“转换方向”。
5.3 季节性
当时间序列中的数据受到季节性因素(例如一年的时间或者一周的时间)的影响时,表示该序列具有季节性 。季节性总是一个已知并且固定的频率。
5.4 周期性
当时间序列数据存在不固定频率的上升和下降时,表示该序列有周期性。周期波动通常至少持续两年。
周期性和季节性的区别:当数据的波动是无规律时,表示序列存在周期性;如果波动的频率不变并且与固定长度的时间段有关,表示序列存在季节性。一般而言,周期的长度较长,并且周期的波动幅度也更大。

【时间序列】周期性检测算法总结
5.5 自相关
指的是时间序列中某一个时刻的值和另一个时刻的值具有一定的相关性。
通常用于时间序列的周期性检测,可以参考:时间序列-周期性检测方法及其 Python 实践
- 当数据具有趋势性时,短期滞后的自相关值较大,因为观测点附近的值波动不会很大。一般是正值,但随着滞后阶数的增加而缓慢下降;
- 当数据具有季节性时,自相关值在滞后阶数与季节周期相同时(或者在季节周期的倍数)较大。
5.6 白噪声
白噪声是一个对所有时间其自相关系数为零的随机过程。即任何两个时间的随机变量都不相关。
对于白噪声而言,我们期望它的自相关值接近0。但是由于随机扰动的存在,自相关值并不会精确地等于0。对于一个长度为T的白噪声序列而言,我们期望在0.95的置信度下,它的自相关值处于±2/√T之间。如果一个序列中有较多的自相关值处于边界之外,那么该序列很可能不是白噪声序列。

在上例中,序列长度 T=50,边界为±2/√50=±0.28。所有的自相关值均落在边界之内,证明序列是白噪声。
5.7 虚假相关性
很多变量间的序列相关性非常强,但是实际上很可能是虚假相关性。

更多虚假相关性案例:Spurious Correlations
许多时间序列同时包含趋势、季节性以及周期性。当我们选择预测方法时,首先应该分析时间序列数据所具备的特征,然后再选择合适的预测方法抓取特征。
六、数据平滑
数据平滑通常是为了消除一些极端值或测量误差。即使有些极端值本身是真实的,但是并没有反映出潜在的数据模式仍需处理。
原理是通过拟合出一个近似的模型来对未来进行预测, 我们可以通过这个预测值和实际的值进行比较, 如果差距过大, 我们就可以判定这个点是异常的。目前存在多种数据平滑方法:
6.1 moving average
即移动平均,给定一个时间序列和窗口长度N,moving average等于当前data point之前N个点(包括当前点)的平均值。不停地移动这个窗口,就得到移动平均曲线。
6.2 cumulative moving average
即累加移动平均:

6.3 Weighted moving averaging
即加权移动平均:

6.4 Exponential smoothing
一次指数平滑,从最邻近到最早的数据点的权重呈现指数型下降的规律。指数平滑算法只有一个参数。
适用:针对没有趋势且没有季节性的序列。
指数移动与移动平均的区别:
- 并没有时间窗口,用的是从时间序列第一个data point到当前data point之间的所有点;
- 每个data point的权重不同,离当前时间点越近的点的权重越大,历史时间点的权重随着离当前时间点的距离呈指数衰减,从当前data point往前的data point,权重依次为
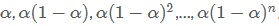
6.5 Holt exponential smoothing
二次指数平滑,通过引入一个额外的系数来解决指数平滑无法应用于具有趋势性数据的问题。
适用:针对有趋势但没有季节性的序列。
6.6 Holt-Winters exponential smoothing
三次指数平滑,通过再次引入一个新系数的方式同时解决了 Holt exponential smoothing 无法解决具有季节性变化数据的不足。
所有的指数平滑法都要更新上一时间步长的计算结果,并使用当前时间步长的数据中包含的新信息。通过”混合“新信息和旧信息来实现,而相关的新旧信息的权重由一个可调整的参数来控制。
七、异常检测分析步骤
面对一个全新的异常检测问题,建议遵循以下步骤分析:
- 我们对于数据有多少了解?数据分布是什么样的?异常分布可能是什么样的?在了解这点后可根据假设选择模型。
- 我们解决的问题是否有标签?如果有的话,我们应该优秀使用监督学习来解决问题。标签信息非常宝贵,不要浪费。
- 如果可能的话,尝试多种不同的算法,尤其是我们对于数据的了解有限时。
- 可以根据数据的特点选择算法,比如中小数据集低维度的情况下可以选择KNN,大数据集高维度HBOS,在特征独立时可能有奇效。
- 无监督异常检测验证模型结果并不容易,可以采用半自动的方式:置信度高的自动放过,置信度低的人工审核。
- 意识到异常的趋势和特征往往处于变化过程中。比如明天的异常数据和今天的可能不同,因此需要不断的重新训练模型及调整策略。
- 不要完全依赖模型,尝试使用半自动化的策略:人工规则+检测模型。很多经验总结下来的人工规则是很有用的,不要尝试一步到位的使用数据策略来代替现有规则。
八、异常检测方法
通常,异常检测算法应该将每个时间点标记为异常/非异常,或者预测某个点的信号,并衡量这个点的真实值与预测值的差值是否足够大,从而将其视为异常。使用后面的方法,你将能够得到一个可视化的置信区间,这有助于理解为什么会出现异常并进行验证。
从分类看,当前发展阶段的时序异常检测算法和模型可以分为以下几类:

- 统计模型:优点是复杂度低,计算速度快,泛化能力强悍。因为没有训练过程,即使没有前期的数据积累,也可以快速的投入生产使用。缺点是准确率一般。但是这个其实是看场景的,并且也有简单的方法来提高业务层面的准确率。这个后面会提到。
- 机器学习模型:鲁棒性较好,准确率较高。需要训练模型,泛化能力一般。
- 深度学习模型:普遍需要喂大量的数据,计算复杂度高。整体看,准确性高,尤其是近段时间,强化学习的引入,进一步巩固其准确性方面的领先优势。
下边就具体算法进行详细总结。
8.1 概率与统计模型
主要是对数据的分布做出假设,并找出假设下所定义的“异常”,因此往往会使用极值分析或者假设检验。比如对最简单的一维数据假设高斯分布,然后将距离均值特定范围以外的数据当做异常点。而推广到高位后,可以假设每个维度各自独立,并将各个维度上的异常度相加。如果考虑特征之间的相关性,也可以用马氏距离来衡量数据的异常度。
优点:
- 最大的优点是速度一般比较快。
- 适合低维数据、鲁棒性较好
缺点:
- 由于存在比较强的“假设”,效果不一定很好。
8.1.1 极值分析(箱型图)
8.1.1.1 适用对象
一维特征空间
8.1.1.2 方法描述
数字异常值方法是一维特征空间中最简单的非参数异常值检测方法,异常值是通过IQR(InterQuartile Range)计算得的。
箱形图(Box-plot)又称为盒须图、盒式图或箱线图,是一种用作显示一组数据分散情况资料的统计图。因形状如箱子而得名。如下图所示,绘制箱线图需要一组数据的最大值、最小值、中位数和两个四分位数:
箱线图为我们提供了识别异常值的一个标准:异常值被定义为小于Q1-a*IQR或大于Q3+a*IQR的值,即超出样本上下限之外的数组元素被视为异常值;其中,a为唯一的参数,取值取决于样本数据的分布。

8.1.2 统计假设检验(3σ准则)
8.1.2.1 适用对象
一维特征空间中的参数异常检测方法,比如在反欺诈领域,用户支付金额、支付频次、购买特定商品次数等等,都适用于上述方法。
8.1.2.2 方法描述
3-Sigma原则又称为拉依达准则,该准则定义如下:假设一组检测数据只含有随机误差,对原始数据进行计算处理得到标准差,然后按一定的概率确定一个区间,认为误差超过这个区间的就属于异常值。

统计检验是最直观也最容易的一个方法,通常来说就是:假设原数据服从某个分布(如高斯分布),异常值是分布尾部的数据点,因此远离数据的平均值。首先计算μ和σ ,μ代表均值,σ代表标准差,再计算 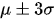 的区间,最后落在区间之外的数据点就被认为是异常值(暗含的思想是,落在尾部分布的数据概率很小了,几乎不可能出现;但是出现了,所以是异常的)。 3-Sigma范围(μ–3σ,μ+3σ)内99.73%的为正常数据。下面是3-Sigma的Python实现:
的区间,最后落在区间之外的数据点就被认为是异常值(暗含的思想是,落在尾部分布的数据概率很小了,几乎不可能出现;但是出现了,所以是异常的)。 3-Sigma范围(μ–3σ,μ+3σ)内99.73%的为正常数据。下面是3-Sigma的Python实现:
import numpy as np
def three_sigma(df_col):'''df_col:DataFrame数据的某一列'''rule = (df_col.mean() - 3 * df_col.std() > df_col) | (df_col.mean() + 3 * df_col.std() < df_col)index = np.arange(df_col.shape[0])[rule]out_range = df_col.iloc[index]return out_range8.1.2.3 存在问题
- 使用3-Sigma的前提是数据服从正态分布。 μ和σ 都对异常值很敏感,在实际计算的时候,异常值也被包含在全部数据集里。对特征异常明显的数据(如下图)来说,上述方法的确有效;但当排除了异常值或者现有数据已经规避了极端异常值后,剩下的新数据集总是能再计算出一对新的 μ和σ ,总是能再找到尾部分布的数值。这时候,这些尾部分布的数据不一定是异常的。

- 只适用于一维数据。但单纯从一维数据上进行风险判别本身就不太靠谱。往往需要结合其他特征进行综合判断,统计方法就不再适用;
8.1.3 时间序列建模(移动平均、指数平滑、ARMA、ARIMA)
- 对于纯随机序列,也称为白噪声序列,序列的各项之间没有任何的关系, 序列在进行完全无序的随机波动, 可以终止对该序列的分析。
- 对于平稳非白噪声序列, 它的均值和方差是常数。ARMA 模型是最常用的平稳序列拟合模型。
- 对于非平稳序列, 由于它的方差和均值不稳定, 处理方法一般是将其转化成平稳序列。 可以使用ARIMA 模型进行分析。
流程:

方法:
1 看时序图
- 始终在一个常数值附近随机波动
- 带有明显趋势性、周期性的,不是平稳序列
2 假设检验
- DF检验
- ADF检验
- KPSS检验
8.1.3.1 自回归(AR)
自回归(AR)方法将序列中的下一步建模为先前时间步骤的观察的线性函数。
该模型的符号涉及指定模型 p 的顺序作为 AR 函数的参数,例如, AR(P)。例如,AR(1)是一阶自回归模型。
该方法适用于没有趋势和季节性成分的单变量时间序列。
8.1.3.2 移动平均线(MA)
移动平均(MA)方法将序列中的下一步建模为来自先前时间步骤的平均过程的残余误差的线性函数。
移动平均模型与计算时间序列的移动平均值不同。
该模型的表示法涉及将模型 q 的顺序指定为 MA 函数的参数,例如, MA(Q)。例如,MA(1)是一阶移动平均模型。
该方法适用于没有趋势和季节性成分的单变量时间序列。
8.1.3.3 自回归移动平均线(ARMA)
自回归移动平均(ARMA)方法将序列中的下一步建模为先前时间步骤的观测和再造误差的线性函数。
它结合了自回归(AR)和移动平均(MA)模型。
该模型的表示法涉及将 AR(p)和 MA(q)模型的顺序指定为 ARMA 函数的参数,例如,ARMA 函数的参数。 ARMA(p,q)。 ARIMA 模型可用于开发 AR 或 MA 模型。
该方法适用于没有趋势和季节性成分的单变量时间序列。
实现:时间序列模式(ARIMA)—Python实现
8.1.3.4 自回归综合移动平均线(ARIMA)
自回归整合移动平均(ARIMA)方法将序列中的下一步建模为先前时间步长的差异观测值和残差误差的线性函数。
它结合了自回归(AR)和移动平均(MA)模型以及序列的差分预处理步骤,使序列静止,称为积分(I)。
该模型的表示法涉及将 AR(p),I(d)和 MA(q)模型的顺序指定为 ARIMA 函数的参数,例如 ARIMA 函数的参数。 ARIMA(p,d,q)。 ARIMA 模型也可用于开发 AR,MA 和 ARMA 模型。
该方法适用于具有趋势且没有季节性成分的单变量时间序列。
8.1.3.5 季节性自回归整合移动平均线(SARIMA)
季节性自回归综合移动平均线(SARIMA)方法将序列中的下一步建模为差异观测值,误差,差异季节观测值和先前时间步长的季节误差的线性函数。
它结合了 ARIMA 模型,能够在季节性水平上执行相同的自回归,差分和移动平均建模。
该模型的表示法涉及指定 AR(p),I(d)和 MA(q)模型的顺序作为 ARIMA 函数和 AR(P),I(D),MA(Q)和 m 的参数。季节性参数,例如 SARIMA(p,d,q)(P,D,Q)m 其中“m”是每个季节(季节性时期)的时间步数。 SARIMA 模型可用于开发 AR,MA,ARMA 和 ARIMA 模型。
该方法适用于具有趋势和/或季节性分量的单变量时间序列。
8.2 基于相似度衡量的模型
异常点因为和正常点的分布不同,因此相似度较低,由此衍生了一系列算法通过相似度来识别异常点。比如最简单的K近邻、基于密度聚类、孤立森林等均可以做异常检测,大部分异常检测算法都可以被认为是一种估计相似度,无论是通过密度、距离、夹角或是划分超平面。通过聚类也可以被理解为一种相似度度量。
8.2.1 基于距离度量-KNN
8.2.1.1 方法描述
认为异常点距离正常点比较远,因此可以对于每一个数据点,计算它的K-近邻距离,即数据对象与最近的k个点的距离之和(或平均距离),与k个最近点的距离越小,异常分越低;与k个最近点的距离越大,异常分越大。设定一个距离的阈值,距离高于这个阈值,对应的数据对象就是异常点。
或者是将全部样本的K-近邻距离排序,取前n个最大的作为异常点。计算距离时一般使用欧式距离,也可以使用角度距离。
- 步骤一:输入数据集D,参数k、n;
- 步骤二:对于每个点计算它的k邻近距离;
- 步骤三:按照距离降序排序;
- 步骤四:前N个点认为是离群点
8.2.1.2 优缺点
优点:
- 不需要假设数据的分布
缺点:
- 不适合高维数据
- 只能找出异常点,无法找出异常簇
- 每一次计算近邻距离都需要遍历整个数据集,不适合大数据及在线应用
- 参数K和阈值需要人工调参
- 当正常点较少、异常点较多时,该方法效果较差
- 当使用欧式距离时,即默认是假设数据是球状分布,因此在边界处不容易识别异常
仅可以找出全局异常点,无法找到局部异常点
另外的,对于多变量数据。采用马氏距离:用来计算样本X与中心点μ的距离,也可以用来做异常分值,计算方式:
![]()
马氏距离最强大的地方是引入了数据之间的相关性(协方差矩阵)。 而且马氏距离不需要任何参数,这对无监督学习来说无疑是一件很好的方法。通常一个简单的最近邻算法加上马氏距离就是一个很好的检测模型。
项目参考:马氏距离+ KNN
8.2.2 基于聚类
基于聚类的异常检测优缺点:
优点:
- 测试阶段会很快,以内只需要和有限个簇比较
- 有些聚类算法(k-means)可以在线应用(准实时)
缺点:
- 异常检测效果很大程度上依赖于聚类效果,但是聚类算法主要目的是聚类,并不是为了异常检测
- 大数据聚类计算开销比较大
此类方法主要有三种假设,三种假设下有各自的方法。计算复杂度很大程度上取决于聚类算法的计算复杂度。
假设一:不属于任何聚类的点是异常点,主要方法包括DBSCAN、SNN clustering、FindOut algorithm、WaveCluster Algorithm。
缺点:不能发现异常簇
该技术基于DBSCAN聚类方法,DBSCAN是一维或多维特征空间中的非参数,基于密度的离群值检测方法。
DBSCAN算法在聚类过程中主要通过寻找核心对象来不断扩展密度可达的样本,从而将样本空间中不同位置的高密度空间找出来。除了高密度空间外的其它不属于任何类簇的样本就被视为异常点。
在DBSCAN聚类技术中,所有数据点都被定义为核心点(Core Points)、边界点(Border Points)或噪声点(Noise Points)。
- 核心点是在距离ℇ内至少具有最小包含点数(minPTs)的数据点;
- 边界点是核心点的距离ℇ内邻近点,但包含的点数小于最小包含点数(minPTs);
- 所有的其他数据点都是噪声点,也被标识为异常值;
从而,异常检测取决于所要求的最小包含点数、距离ℇ和所选择的距离度量,比如欧几里得或曼哈顿距离。
假设二:距离最近的聚类结果较远的点是异常点,主要方法包括K-Means、Self-Organizing Maps(SOM)、GMM。
首先进行聚类,然后计算样例与其所属聚类中心的距离,计算其所属聚类的类内平均距离,用两者的比值衡量异常程度。
缺点:不能发现异常簇
假设三:稀疏聚类和较小的聚类里的点都是异常点,主要方法包括CBLOF、LDCOF、CMGOS等。
首先进行聚类,然后启发式地将聚类簇分成大簇和小簇。如果某一样例属于大簇,则利用该样例和其所属大簇计算异常得分,如果某一样例属于小簇,则利用该样例和距离其最近的大簇计算异常得分。三种算法的区别在于计算异常得分的方式不同
优点:考虑到了数据全局分布和局部分布的差异,可以发现异常簇
8.3 集成异常检测与模型融合
在无监督学习时,提高模型的鲁棒性很重要,因此集成学习就大有用武之地。比如上面提到的Isolation Forest,就是基于构建多棵决策树实现的。
8.3.1 孤立森林
Isolation Forest,也称IForest。
8.3.1.1 适用对象
一维或多维特征空间中大数据集的非参数方法。适合高维数据上的异常检测。
![]()
8.3.1.2 方法描述
该方法一个重要概念是孤立数。孤立数是孤立数据点所需的拆分数。通过以下步骤确定此分割数:
- 随机选择要分离的点“a”;
- 选择在最小值和最大值之间的随机数据点“b”,并且与“a”不同;
- 如果“b”的值低于“a”的值,则“b”的值变为新的下限;
- 如果“b”的值大于“a”的值,则“b”的值变为新的上限;
- 只要在上限和下限之间存在除“a”之外的数据点,就重复该过程;
与孤立非异常值相比,它需要更少的分裂来孤立异常值,即异常值与非异常点相比具有更低的孤立数。因此,如果数据点的孤立数低于阈值,则将数据点定义为异常值。
阈值是基于数据中异常值的估计百分比来定义的,这是异常值检测算法的起点。contamination是异常值占比,是IsolationForest的一个核心参数。预设的异常值占比越接近真实占比,模型效果越好。
实现:iForest (Isolation Forest)孤立森林 异常检测 入门篇
8.3.1.3 存在问题
- 工业应用时,作为一个纯粹的无监督算法,异常值占比多少,并没有一个很好的衡量标准。因此,模型上线后,仍然需要投入人力进行样本标注,才能对模型进行迭代优化。
8.3.1.4 资料补充
paper地址:Isolation-based Anomaly Detection
8.3.2 深度学习
8.3.2.1 介绍
基于深度学习的时间序列异常检测算法,主要可以分为以下这么几种
- 针对正常数据进行训练建模,然后通过高重构误差来识别异常点,即生成式(Generative)的算法,往往是无监督的,如自编码器(Auto Encoder)类,或者回声状态网络(Echo State Networks)。
- 对数据的概率分布进行建模,然后根据样本点与极低概率的关联性来识别异常点,如DAGMM。
- 通过标注数据,告诉模型正常数据点长什么样,异常数据点长什么样,然后通过有监督算法训练分类模型,也称判别式(Discriminative)算法。
在判别式里面,包括时间序列的特征工程和各种有监督算法,还有端到端的深度学习方法。在端到端的深度学习方法里面,包括前馈神经网络,卷积神经网络,或者其余混合模型等常见算法。借用张大大的图大致做一个总结:

8.3.2.2 几种深度学习方法 + 代码实例
1)基于AutoEncoder的无监督异常检测算法(Tensorflow)
可以参考一篇博文:【深度学习】 自编码器(AutoEncoder)
2)Deep SVDD:来自论文Deep One-Class Classification
3)基于Transformer掩码重建的时序数据异常检测算法(pyTorch)
可以参考一篇博文:【深度学习】Transformer详解
九、资源 Useful links
1、开源Python异常检测工具库PyOD项目地址:https://github.com/yzhao062/Pyod
2、异常检测学习资源:https://github.com/yzhao062/anomaly-detection-resources
3、腾讯异常检测开源学件Metis:https://github.com/Tencent/Metis
十、后记
此外,在业务的实际场景下,异常点的检测有的时候只是一种辅助手段,帮助机器学习从业者迅速定位异常。但是,如果要保证效果和输出的话,最好是在定位了异常之后,把数据保存下来当做样本和标签,然后建立一个有监督学习的模型。这样通常来说就能够解决不少的问题。通常的套路都是:
原始数据 -> 无监督算法 -> 人工标注 -> 特征工程 -> 有监督算法
参考
时间序列丨基础概念理论 & 异常检测算法 & 相关学习资源 & 公开数据集
2-1 异常检测(Anomaly detection)方法小结
基于时间序列的异常检测算法小结
【时间序列】时间序列的智能异常检测方案
python中的经典时间序列预测方法
时间序列异常检测(一)—— 算法综述
网络KPI异常检测之时序分解算法
《预测:方法与实践》
查看全文
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.dgrt.cn/a/85537.html
如若内容造成侵权/违法违规/事实不符,请联系一条长河网进行投诉反馈,一经查实,立即删除!
相关文章:
异常检测主要方法总结
最近对预测及异常检测进行了一些研究和学习,把所学东西做一个汇总整理。欢迎交流拍砖 👏(侵权删) 目录
一、时间序列概念
二、时间序列异常检测
三、时序类型
四、异常类型
4.1 点异常
4.2 上下文异常
4.3 集合异常
五、重……
编程日记2022/10/17 16:42:00
安全防护-笔记-待完善
安全防护框架汇报:
防火墙、Ip池、应用层
防DDos WAF 云安全中心 云防火墙 SSL
分布式拒绝服务攻击:恶意流量攻击通常指的是DDOS攻击,加机器加贷款。 高仿的IP清洗。 CDN
1、如果接入阿里的DDOS高仿设备,后续流量进来通过……
编程日记2022/10/17 16:41:28
微信小程序开发实战9_3 小程序URL Scheme
为了微信小程序的推广,微信提供了多种小程序入口方式,比如在公众号中可以将已经关联过的小程序的页面放置到自定义菜单中,用户单击后就可以打开小程序的相关页面;或者是给用户发送公众号模板消息,用户点击收到的模板消息进入小程序。不过这些方式都需要微信客户端的支持,……
编程日记2022/10/17 16:40:56
CMake – 概览
关于CMake
CMake是一个可扩展的、开源的系统,在操作系统中使用它时,它以与编译器无关的方式管理的软件构建过程。与许多跨平台系统不同,CMake被设计为与本地构建环境一起使用。放在每个源代码目录下的简单配置文件(称为CMakeList……
编程日记2022/10/17 16:40:23
MacOS使用Nvim+LaTeX+Skim配置高效的论文写作环境
tags: Vim LaTeX Tips Lua
写在前面
折腾一下在Mac上配置neovim写LaTeX的环境, 以及skim阅读器的配置. 这里参考了一位朋友的配置1, 我改成了在mac上使用的配置了.
vimtex配置
function config.vimtex()vim.g.tex_flavorlatex — Default tex file formatvim.g.vimtex_view……
编程日记2022/10/17 16:39:48
阿里云容器服务-kubermetes集群无操作权限
一、背景
当你尝试访问不是你创建的ACK时,你可能会遇到以下错误 二、获得Kubernetes用户名
ASCM用户登录您的阿里云平台,并向下砖取到您的集群下的ACK服务在”集群信息“页签下,点击进入“连接信息”页签在集群凭证种获取用户名,……
编程日记2022/10/17 16:39:14
1.3.5 手写数字识别之资源配置
文章目录概述前提条件一、单GPU训练二、分布式训练模型并行数据并行PRC通信方式NCCL2通信方式(Collective)1. 基于launch方式启动单机单卡启动,默认使用第0号卡。单机多卡启动,默认使用当前可见的所有卡。单机多卡启动,……
编程日记2022/10/17 16:38:39
【云原生之Docker实战】使用Docker部署image2df工具
【云原生之Docker实战】使用Docker部署image2df工具 一、image2df简介二、检查本地docker环境1.检查docker版本2.检查docker状态三、下载image2df镜像四、将docker临时容器配置命令别名1.设置alias别名2.激活环境变量文件五、测试转化dockerfile效果1.下载mysql镜像2.生成docke……
编程日记2022/10/17 16:38:06
《变量4》读书笔记
文章目录书籍信息腾挪新型确定性年代腾挪破局点我打我的改变约束条件没戏了先生来自未来的你远方和故乡望乡六盘山下“吊庄”的腾挪忠诚、退出、呼吁,以及腾挪边缘和中心小镇明星边缘绽放贾胖子中心谦让穿越周期的力量一根丝与周期交锋周期与波动总赢率先有车&#……
编程日记2022/10/17 16:37:32
【PyTorch深度学习项目实战100例】—— 基于Transformer实现100项体育运动分类 | 第48例
前言
大家好,我是阿光。
本专栏整理了《PyTorch深度学习项目实战100例》,内包含了各种不同的深度学习项目,包含项目原理以及源码,每一个项目实例都附带有完整的代码+数据集。
正在更新中~ ✨
🚨 我的项目环境: 平台:Windows10语言环境:python3.7编译器:PyCharmPy……
编程日记2022/10/17 16:36:59
Java 进阶(15)线程安全集合
CopyOnWriteArrayList
线程安全的ArrayList,加强版读写分离。
写有锁,读⽆锁,读写之间不阻塞,优于读写锁。
写⼊时,先copy⼀个容器副本、再添加新元素,最后替换引⽤。
使⽤⽅式与ArrayList⽆异。
示例……
编程日记2023/4/16 14:57:08
HR:面试官最爱问的linux问题,看看你能答对多少
文章目录摘要Linux的文件系统是什么样子的?如何访问和管理文件和目录?如何在Linux中查看和管理进程?如何使用Linux命令行工具来查看系统资源使用情况?如何配置Linux系统的网络设置?如何使用Linux的cron任务调度器来执行……
编程日记2023/4/16 14:56:56
vscode开发常用的工具栏选项,查看源码技巧以及【vscode常用的快捷键】
一、开发常用的工具栏选项
1、当前打开的文件快速在左侧资源树中定位: 其实打开了当前的文件已经有在左侧资源树木定位了,只是颜色比较浅 2、打开太多文件的时候,可以关闭 3、设置查看当前类或文件的结构 OUTLINE
相当于idea 查看当前类或接……
编程日记2023/4/16 14:56:45
数据要素化条件之一:原始性
随着技术的发展,计算机不仅成为人类处理信息的工具,而且逐渐地具有自主处理数据的能力,出现了替代人工的数据智能技术。数据智能的大规模使用需要关于同一分析对象或同一问题的、来源于不同数据源的海量数据。这种数据必须是针对特定对象的记……
编程日记2023/4/16 14:56:36
【面试题 高逼格利用 类实现加法】编写代码, 实现多线程数组求和.
编写代码, 实现多线程数组求和.关键1. 数组的初始化关键2. 奇偶的相加import java.util.Random;public class Thread_2533 {public static void main(String[] args) throws InterruptedException {// 记录开始时间long start System.currentTimeMillis();// 1. 给定一个很长的……
编程日记2023/4/16 14:56:10
一个python训练
美国:28:麻省理工学院,斯坦福大学,哈佛大学,加州理工学院,芝加哥大学,普林斯顿大学,宾夕法尼亚大学,耶鲁大学,康奈尔大学,哥伦比亚大学,密歇根大学安娜堡分校,约翰霍普金斯大学,西北大学,加州大学伯克利分校,纽约大学,加州大学洛杉矶分校,杜克大学,卡内基梅隆大学,加州大学圣地……
编程日记2023/4/16 14:55:59
Mybatis03学习笔记
目录 使用注解开发
设置事务自动提交
mybatis运行原理
注解CRUD
lombok使用(偷懒神器,大神都不建议使用)
复杂查询环境(多对一)
复杂查询环境(一对多)
动态sql环境搭建
动态sql常用标签……
编程日记2023/4/16 14:55:50
设置或取得c# NumericUpDown 编辑框值的方法,(注意:不是Value值)
本人在C#开发中使用到了NumericUpDown控件,但是发现该控件不能直接控制显示值,经研究得到下面的解决办法
NumericUpDown由于是由多个控件组合而来的控件,其中包含一个类似TextBox的控件,若想取得或改变其中的值要使用如下方法
N……
编程日记2023/4/16 14:55:46
使用NPOI 技术 的SetColumnWidth 精确控制列宽不能成功的解决办法(C#)
在使用NPOI技术开发自动操作EXCEL软件时遇到不能精确设置列宽的问题。
如
ISheet sheet1 hssfworkbook.CreateSheet("Sheet1");
sheet1.SetColumnWidth(0, 50 * 256); // 在EXCEL文档中实际列宽为49.29
sheet1.SetColumnWidth(1, 100 * 256); // 在EXCEL文……
编程日记2023/4/16 14:55:46
Mysql 数据库zip版安装时basedir datadir 路径设置问题,避免转义符的影响
本人在开发Mysql数据库自动安装程序时遇到个很奇怪的问题,其中my.ini的basedir 的路径设置是下面这样的:
basedir d:\测试\test\mysql
但是在使用mysqld安装mysql服务时老是启动不了,报1067错误,后来查看window事件发现一个独特……
编程日记2023/4/16 14:55:45