文章目录[隐藏]
- 1. 感知机
- 2. 多层感知机(神经网络)
- 3. 误差逆传播(error BackPropagation,简称BP)算法
- 4. 深度学习
- 5. 卷积神经网络(Convolutional Neural Networks, CNN)
- 6. 递归(循环)神经网络(Recurrent Neural Networks,简称RNN)
- RNN的改进1:双向RNN
- RNN的改进2:深层双向RNN
- 7. 长短时记忆单元(Long-Short Term Memory,简称LSTM)
- 双向LSTM
- 神经网络/深度学习
- FIFO,LRU,OPT置换算法
- 单独的FIFO
- FIFO,LRU,OPT页面置换算法
- 首次适应算法和最佳适应算法和循环首次适应算法和最坏适应算法
- 进程调度的优先数法和简单轮转法
- 服务器端用Servlet响应客户端请求,Gson请求。可以返回多个数据库中的信息
- Linux Apache2.2配置CGI
- linux下安装配置DBI,perl连接mysql
- 【MySQL】实验九 关系代数
- python以及PyCharm工具的环境安装与配置
- JavaScript【六】JavaScript中的字符串(String)
- 获取文件MD5小案例(未拆分文件)
- Java 进阶(15)线程安全集合
- HR:面试官最爱问的linux问题,看看你能答对多少
- vscode开发常用的工具栏选项,查看源码技巧以及【vscode常用的快捷键】
- 数据要素化条件之一:原始性
- 【面试题 高逼格利用 类实现加法】编写代码, 实现多线程数组求和.
- 一个python训练
- Mybatis03学习笔记
https://github.com/apachecn/AiLearning
https://github.com/imhuay/Algorithm_Interview_Notes-Chinese
1. 感知机
感知机(perceptron)是由两层神经元组成的结构,输入层用于接受外界输入信号,输出层(也被称为是感知机的功能层)就是M-P神经元。感知机是一种判别式的线性分类模型,可以解决与、或、非这样的简单的线性可分(linearly separable)问题,线性可分问题的示意图见下图:



2. 多层感知机(神经网络)
引出非线性问题,多层感知机。我们通常将多层感知机这样的多层结构称之为是神经网络。


神经网络的预备知识
(1)为什么要用神经网络?
特征提取的高效性。
一个分类任务,用机器学习算法来做时,首先要明确feature和label,然后把这个数据"灌"到算法里去训练,最后保存模型,再来预测分类的准确性。但是这就有个问题,即我们需要实现确定好特征,每一个特征即为一个维度,特征数目过少,我们可能无法精确的分类出来,即我们所说的欠拟合,如果特征数目过多,可能会导致我们在分类过程中过于注重某个特征导致分类错误,即过拟合。
举个简单的例子,现在有一堆数据集,让我们分类出西瓜和冬瓜,如果只有两个特征:形状和颜色,可能没法分区来;如果特征的维度有:形状、颜色、瓜瓤颜色、瓜皮的花纹等等,可能很容易分类出来;如果我们的特征是:形状、颜色、瓜瓤颜色、瓜皮花纹、瓜蒂、瓜籽的数量,瓜籽的颜色、瓜籽的大小、瓜籽的分布情况、瓜籽的XXX等等,很有可能会过拟合,譬如有的冬瓜的瓜籽数量和西瓜的类似,模型训练后这类特征的权重较高,就很容易分错。这就导致我们在特征工程上需要花很多时间和精力,才能使模型训练得到一个好的效果。然而神经网络的出现使我们不需要做大量的特征工程,譬如提前设计好特征的内容或者说特征的数量等等,我们可以直接把数据灌进去,让它自己训练,自我“修正”,即可得到一个较好的效果。
数据格式的简易性
在一个传统的机器学习分类问题中,我们“灌”进去的数据是不能直接灌进去的,需要对数据进行一些处理,譬如量纲的归一化,格式的转化等等,不过在神经网络里我们不需要额外的对数据做过多的处理,具体原因可以看后面的详细推导。
参数数目的少量性
在面对一个分类问题时,如果用SVM来做,我们需要调整的参数需要调整核函数,惩罚因子,松弛变量等等,不同的参数组合对于模型的效果也不一样,想要迅速而又准确的调到最适合模型的参数需要对背后理论知识的深入了解(当然,如果你说全部都试一遍也是可以的,但是花的时间可能会更多),对于一个基本的三层神经网络来说(输入-隐含-输出),我们只需要初始化时给每一个神经元上随机的赋予一个权重w和偏置项b,在训练过程中,这两个参数会不断的修正,调整到最优质,使模型的误差最小。所以从这个角度来看,我们对于调参的背后理论知识并不需要过于精通(只不过做多了之后可能会有一些经验,在初始值时赋予的值更科学,收敛的更快罢了)
(2)有哪些应用?
应用非常广,不过大家注意一点,我们现在所说的神经网络,并不能称之为深度学习,神经网络很早就出现了,只不过现在因为不断的加深了网络层,复杂化了网络结构,才成为深度学习,并在图像识别、图像检测、语音识别等等方面取得了不错的效果。
(3)基本网络结构
一个神经网络最简单的结构包括输入层、隐含层和输出层,每一层网络有多个神经元,上一层的神经元通过激活函数映射到下一层神经元,每个神经元之间有相对应的权值,输出即为我们的分类类别。
(4)优缺点
前面说了很多优点,这里就不多说了,简单说说缺点吧。我们试想一下如果加深我们的网络层,每一个网络层增加神经元的数量,那么参数的个数将是M*N(m为网络层数,N为每层神经元个数),所需的参数会非常多,参数一多,模型就复杂了,越是复杂的模型就越不好调参,也越容易过拟合。此外我们从神经网络的反向传播的过程来看,梯度在反向传播时,不断的迭代会导致梯度越来越小,即梯度消失的情况,梯度一旦趋于0,那么权值就无法更新,这个神经元相当于是不起作用了,也就很难导致收敛。尤其是在图像领域,用最基本的神经网络,是不太合适的。后面我们会详细讲讲为啥不合适。
3. 误差逆传播(error BackPropagation,简称BP)算法
BP学习算法通常用在最为广泛使用的多层前馈神经网络中。

神经网络中的反向传播法
https://www.cnblogs.com/charlotte77/p/5629865.html
(1)初始权重
(2)计算输出值:输入层—->隐含层—->输出层(每层激活函数)
(3)计算总误差:e_all ![]()
(4)隐含层—->输出层的权值更新:
a.整体误差e_all对w5的偏导值

(链式法则)(从输出往输入)
b.更新权值
 是学习速率.
是学习速率.
(5)隐含层—->隐含层的权值更新:
方法其实与上面说的差不多,但是有个地方需要变一下,在上文计算总误差对w5的偏导时,是从out(o1)—->net(o1)—->w5,但是在隐含层之间的权值更新时,是out(h1)—->net(h1)—->w1,而out(h1)会接受E(o1)和E(o2)两个地方传来的误差,所以这个地方两个都要计算。

BP算法存在的问题:(传统神经网络的训练方法为什么不能用在深度神经网络)
(1)梯度越来越稀疏:从顶层越往下,误差校正信号越来越小;
(2)收敛到局部最小值:尤其是从远离最优区域开始的时候(随机值初始化会导致这种情况的发生);
(3)一般,我们只能用有标签的数据来训练:但大部分的数据是没标签的,而大脑可以从没有标签的的数据中学习。
4. 深度学习
深度学习指的是深度神经网络模型,一般指网络层数在三层或者三层以上的神经网络结构。
参数越多的模型复杂度越高,“容量”也就越大,也就意味着它能完成更复杂的学习任务。但是在一般情况下,复杂模型的训练效率低,易陷入过拟合,因此难以受到人们的青睐。具体来讲就是,随着神经网络层数的加深,优化函数越来越容易陷入局部最优解(即过拟合,在训练样本上有很好的拟合效果,但是在测试集上效果很差)。同时,不可忽略的一个问题是随着网络层数增加,“梯度消失”(或者说是梯度发散diverge)现象更加严重。我们经常使用sigmoid函数作为隐含层的功能神经元,对于幅度为1的信号,在BP反向传播梯度时,每传递一层,梯度衰减为原来的0.25。层数一多,梯度指数衰减后低层基本接收不到有效的训练信号。
为了解决深层神经网络的训练问题,一种有效的手段是采取无监督逐层训练(unsupervised layer-wise training),其基本思想是每次训练一层隐节点,训练时将上一层隐节点的输出作为输入,而本层隐节点的输出作为下一层隐节点的输入,这被称之为“预训练”(pre-training);在预训练完成后,再对整个网络进行“微调”(fine-tunning)训练。比如Hinton在深度信念网络(Deep Belief Networks,简称DBN)中,每层都是一个RBM,即整个网络可以被视为是若干个RBM堆叠而成。在使用无监督训练时,首先训练第一层,这是关于训练样本的RBM模型,可按标准的RBM进行训练;然后,将第一层预训练号的隐节点视为第二层的输入节点,对第二层进行预训练;… 各层预训练完成后,再利用BP算法对整个网络进行训练。
另一种节省训练开销的做法是进行“权共享”(weight sharing),即让一组神经元使用相同的连接权,这个策略在卷积神经网络(Convolutional Neural Networks,简称CNN)中发挥了重要作用。CNN可以用BP算法进行训练,但是在训练中,无论是卷积层还是采样层,其每组神经元(即上图中的每一个“平面”)都是用相同的连接权,从而大幅减少了需要训练的参数数目。
5. 卷积神经网络(Convolutional Neural Networks, CNN)
https://www.cnblogs.com/charlotte77/p/7759802.html
在图像领域,每个像素点有三个通道,分别代表RGB颜色,那么,如果一个图像的尺寸是(28,28,1),即代表这个图像的是一个长宽均为28,channel为1的图像(channel也叫depth,此处1代表灰色图像)。如果使用全连接的网络结构,即,网络中的神经与与相邻层上的每个神经元均连接,那就意味着我们的网络有28 * 28 =784个神经元,hidden层采用了15个神经元,那么简单计算一下,我们需要的参数个数(w和b)就有:7841510+15+10=117625个。
传统的三层神经网络需要大量的参数,原因在于每个神经元都和相邻层的神经元相连接,但是思考一下,这种连接方式是必须的吗?全连接层的方式对于图像数据来说似乎显得不这么友好,因为图像本身具有“二维空间特征”,通俗点说就是局部特性。譬如我们看一张猫的图片,可能看到猫的眼镜或者嘴巴就知道这是张猫片,而不需要说每个部分都看完了才知道,啊,原来这个是猫啊。所以如果我们可以用某种方式对一张图片的某个典型特征识别,那么这张图片的类别也就知道了。这个时候就产生了卷积的概念。
(1)卷积层(Convolutional Layer)
举个例子,现在有一个44的图像,我们设计两个卷积核,看看运用卷积核后图片会变成什么样。
由下图可以看到,原始图片是一张灰度图片,每个位置表示的是像素值,0表示白色,1表示黑色,(0,1)区间的数值表示灰色。对于这个44的图像,我们采用两个22的卷积核来计算。设定步长为1,即每次以22的固定窗口往右滑动一个单位。

paddlepaddle里是这样定义的:
1 conv_pool_1 = paddle.networks.simple_img_conv_pool(
2 input=img,
3 filter_size=3,
4 num_filters=2,
5 num_channel=1,
6 pool_stride=1,
7 act=paddle.activation.Relu())
所以这个卷积过程就完成了。从上文的计算中我们可以看到,同一层的神经元可以共享卷积核,那么对于高位数据的处理将会变得非常简单。并且使用卷积核后图片的尺寸变小,方便后续计算,并且我们不需要手动去选取特征,只用设计好卷积核的尺寸,数量和滑动的步长就可以让它自己去训练了,省时又省力啊。
那么问题来了,虽然我们知道了卷积核是如何计算的,但是为什么使用卷积核计算后分类效果要由于普通的神经网络呢?我们仔细来看一下上面计算的结果。通过第一个卷积核计算后的feature_map是一个三维数据,在第三列的绝对值最大,说明原始图片上对应的地方有一条垂直方向的特征,即像素数值变化较大;而通过第二个卷积核计算后,第三列的数值为0,第二行的数值绝对值最大,说明原始图片上对应的地方有一条水平方向的特征。
为什么卷积核有效?
仔细思考一下,这个时候,我们设计的两个卷积核分别能够提取,或者说检测出原始图片的特定的特征。此时我们其实就可以把卷积核就理解为特征提取器啊!现在就明白了,为什么我们只需要把图片数据灌进去,设计好卷积核的尺寸、数量和滑动的步长就可以让自动提取出图片的某些特征,从而达到分类的效果!
注:
- 此处的卷积运算是两个卷积核大小的矩阵的内积运算,不是矩阵乘法。即相同位置的数字相乘再相加求和。不要弄混淆了。
- 卷积核的公式有很多,这只是最简单的一种。我们所说的卷积核在数字信号处理里也叫滤波器,那滤波器的种类就多了,均值滤波器,高斯滤波器,拉普拉斯滤波器等等,不过,不管是什么滤波器,都只是一种数学运算,无非就是计算更复杂一点。
- 每一层的卷积核大小和个数可以自己定义,不过一般情况下,根据实验得到的经验来看,会
在越靠近输入层的卷积层设定少量的卷积核,越往后,卷积层设定的卷积核数目就越多。具体原因大家可以先思考一下,小结里会解释原因。
(2)池化层(Pooling Layer)
通常来说,池化方法一般有一下两种:
- MaxPooling:取滑动窗口里最大的值
- AveragePooling:取滑动窗口内所有值的平均值
通过上一层22的卷积核操作后,我们将原始图像由44的尺寸变为了33的一个新的图片。池化层的主要目的是通过降采样的方式,在不影响图像质量的情况下,压缩图片,减少参数。简单来说,假设现在设定池化层采用MaxPooling,大小为22,步长为1,取每个窗口最大的数值重新,那么图片的尺寸就会由33变为22:(3-2)+1=2。从上例来看,会有如下变换:

为什么采用Max Pooling?
从计算方式来看,算是最简单的一种了,取max即可,但是这也引发一个思考,为什么需要Max Pooling,意义在哪里?如果我们只取最大值,那其他的值被舍弃难道就没有影响吗?不会损失这部分信息吗?如果认为这些信息是可损失的,那么是否意味着我们在进行卷积操作后仍然产生了一些不必要的冗余信息呢?
其实从上文分析卷积核为什么有效的原因来看,每一个卷积核可以看做一个特征提取器,不同的卷积核负责提取不同的特征,我们例子中设计的第一个卷积核能够提取出“垂直”方向的特征,第二个卷积核能够提取出“水平”方向的特征,那么我们对其进行Max Pooling操作后,提取出的是真正能够识别特征的数值,其余被舍弃的数值,对于我提取特定的特征并没有特别大的帮助。那么在进行后续计算使,减小了feature map的尺寸,从而减少参数,达到减小计算量,缺不损失效果的情况。
不过并不是所有情况Max Pooling的效果都很好,有时候有些周边信息也会对某个特定特征的识别产生一定效果,那么这个时候舍弃这部分“不重要”的信息,就不划算了。所以具体情况得具体分析,如果加了Max Pooling后效果反而变差了,不如把卷积后不加Max Pooling的结果与卷积后加了Max Pooling的结果输出对比一下,看看Max Pooling是否对卷积核提取特征起了反效果。
Zero Padding(补零)
所以到现在为止,我们的图片由44,通过卷积层变为33,再通过池化层变化22,如果我们再添加层,那么图片岂不是会越变越小?这个时候我们就会引出“Zero Padding”(补零),它可以帮助我们保证每次经过卷积或池化输出后图片的大小不变,如,上述例子我们如果加入Zero Padding,再采用33的卷积核,那么变换后的图片尺寸与原图片尺寸相同,如下图所示:

通常情况下,我们希望图片做完卷积操作后保持图片大小不变,所以我们一般会选择尺寸为33的卷积核和1的zero padding,或者55的卷积核与2的zero padding,这样通过计算后,可以保留图片的原始尺寸。那么加入zero padding后的feature_map尺寸 =( width + 2 * padding_size – filter_size )/stride + 1
注:这里的width也可换成height,此处是默认正方形的卷积核,weight = height,如果两者不相等,可以分开计算,分别补零。
(3)Flatten层 & Fully Connected Layer
到这一步,其实我们的一个完整的“卷积部分”就算完成了,如果想要叠加层数,一般也是叠加“Conv-MaxPooing",通过不断的设计卷积核的尺寸,数量,提取更多的特征,最后识别不同类别的物体。做完Max Pooling后,我们就会把这些数据“拍平”,丢到Flatten层,然后把Flatten层的output放到full connected Layer里,采用softmax对其进行分类。

小结
1. 卷积核的尺寸必须为正方形吗?可以为长方形吗?如果是长方形应该怎么计算?
卷积核的尺寸不一定非得为正方形。长方形也可以,只不过通常情况下为正方形。如果要设置为长方形,那么首先得保证这层的输出形状是整数,不能是小数。如果你的图像是边长为 28 的正方形。那么卷积层的输出就满足[ (28 - kernel_size)/ stride ] + 1 ,这个数值得是整数才行,否则没有物理意义。譬如,你算得一个边长为 3.6 的 feature map 是没有物理意义的。 pooling 层同理。FC 层的输出形状总是满足整数,其唯一的要求就是整个训练过程中 FC 层的输入得是定长的。如果你的图像不是正方形。那么在制作数据时,可以缩放到统一大小(非正方形),再使用非正方形的 kernel_size 来使得卷积层的输出依然是整数。总之,撇开网络结果设定的好坏不谈,其本质上就是在做算术应用题:如何使得各层的输出是整数。
2.卷积核的个数如何确定?每一层的卷积核的个数都是相同的吗?
由经验确定,在越靠近输入层的卷积层设定少量的卷积核,越往后,卷积层设定的卷积核数目就越多。通常情况下,靠近输入的卷积层,譬如第一层卷积层,会找出一些共性的特征,如手写数字识别中第一层我们设定卷积核个数为5个,一般是找出诸如"横线"、“竖线”、“斜线”等共性特征,我们称之为basic feature,经过max pooling后,在第二层卷积层,设定卷积核个数为20个,可以找出一些相对复杂的特征,如“横折”、“左半圆”、“右半圆”等特征,越往后,卷积核设定的数目越多,越能体现label的特征就越细致,就越容易分类出来,打个比方,如果你想分类出“0”的数字,你看到这个特征,能推测是什么数字呢?只有越往后,检测识别的特征越多,试过能识别这几个特征,那么我就能够确定这个数字是“0”。
3.步长的向右和向下移动的幅度必须是一样的吗?
有stride_w和stride_h,后者表示的就是上下步长。如果用stride,则表示stride_h=stride_w=stride。
6. 递归(循环)神经网络(Recurrent Neural Networks,简称RNN)
https://blog.csdn.net/qq_39422642/article/details/78676567
既然我们已经有了人工神经网络和卷积神经网络,为什么还要循环神经网络? 原因很简单,无论是卷积神经网络,还是人工神经网络,他们的前提假设都是:元素之间是相互独立的,输入与输出也是独立的,比如猫和狗。
但现实世界中,很多元素都是相互连接的,比如股票随时间的变化,一个人说了:我喜欢旅游,其中最喜欢的地方是云南,以后有机会一定要去_____。这里填空,人应该都知道是填“云南“。因为我们是根据上下文的内容推断出来的,但机会要做到这一步就相当得难了。因此,就有了现在的循环神经网络,他的本质是:像人一样拥有记忆的能力。因此,他的输出就依赖于当前的输入和记忆。
允许网络中出现环形结构,从而可以让一些神经元的输出反馈回来作为输入信号,这样的结构与信息反馈过程,使得网络在t时刻的输出状态不仅与t时刻的输入有关,还与t−1时刻的网络状态有关,从而能处理与时间有关的动态变化。
RNN在(t+1)时刻网络的结果O(t+1)是该时刻输入和所有历史共同作用的结果,这样就达到了对时间序列建模的目的。因此,从某种意义上来讲,RNN被视为是时间深度上的深度学习也未尝不对。这么讲其实也不是很准确,因为“梯度发散”同样也会发生在时间轴上,也就是说对于t时刻来说,它产生的梯度在时间轴上向历史传播几层之后就消失了,根本无法影响太遥远的过去。在实际中,这种影响也就只能维持若干个时间戳而已。


其中每个圆圈可以看作是一个单元,而且每个单元做的事情也是一样的,因此可以折叠呈左半图的样子。用一句话解释RNN,就是一个单元结构重复使用。
RNN是一个序列到序列的模型,假设xt−1, xt, xt+1是一个输入:“我是中国“,那么ot−1, ot就应该对应”是”,”中国”这两个,预测下一个词最有可能是什么?就是ot+1应该是”人”的概率比较大。
因此,我们可以做这样的定义:
Xt: 表示t时刻的输入,ot: 表示t时刻的输出,St: 表示t时刻的记忆。
因为我们当前时刻的输出是由记忆和当前时刻的输入决定的,就像你现在大四,你的知识是由大四学到的知识(当前输入)和大三以及大三以前学到的东西的(记忆)的结合,RNN在这点上也类似,神经网络最擅长做的就是通过一系列参数把很多内容整合到一起,然后学习这个参数,因此就定义了RNN的基础。
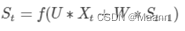
大家可能会很好奇,为什么还要加一个f()函数,其实这个函数是神经网络中的激活函数,但为什么要加上它呢?
举个例子,假如你在大学学了非常好的解题方法,那你初中那时候的解题方法还要用吗?显然是不用了的。RNN的想法也一样,既然我能记忆了,那我当然是只记重要的信息啦,其他不重要的,就肯定会忘记,是吧。但是在神经网络中什么最适合过滤信息呀?肯定是激活函数嘛,因此在这里就套用一个激活函数,来做一个非线性映射,来过滤信息,这个激活函数可能为tanh,也可为其他。
假设你大四快毕业了,要参加考研,请问你参加考研是不是先记住你学过的内容然后去考研,还是直接带几本书去参加考研呢?很显然嘛,那RNN的想法就是预测的时候带着当前时刻的记忆St去预测。假如你要预测“我是中国“的下一个词出现的概率,这里已经很显然了,运用softmax来预测每个词出现的概率再合适不过了,但预测不能直接带用一个矩阵来预测呀,所有预测的时候还要带一个权重矩阵V, 用公式表示为:
ot=softmax(VSt)
其中ot就表示时刻t的输出。
RNN中的结构细节:
- 可以把St当作隐状态,捕捉了之前时间点上的信息。就像你去考研一样,考的时候记住了你能记住的所有信息。
- ot是由当前时间以及之前所有的记忆得到的。就是你考研之后做的考试卷子,是用你的记忆得到的。
- 很可惜的是,St并不能捕捉之前所有时间点的信息。就像你考研不能记住所有的英语单词一样。
- 和卷积神经网络一样,这里的网络中每个cell都共享了一组参数(U,V,W),这样就能极大的降低计算量了。
- ot在很多情况下都是不存在的,因为很多任务,比如文本情感分析,都是只关注最后的结果的。就像考研之后选择学校,学校不会管你到底怎么努力,怎么心酸的准备考研,而只关注你最后考了多少分。
考研,而只关注你最后考了多少分。
RNN反向传播使用BPTT,可能产生梯度消失/梯度爆炸
https://zhuanlan.zhihu.com/p/85776566
RNN的改进1:双向RNN
在有些情况,比如有一部电视剧,在第三集的时候才出现的人物,现在让预测一下在第三集中出现的人物名字,你用前面两集的内容是预测不出来的,所以你需要用到第四,第五集的内容来预测第三集的内容,这就是双向RNN的想法。如图是双向RNN的图解:


这里的 ![]() 做的是一个拼接,如果他们都是1000X1维的,拼接在一起就是1000X2维的了。
做的是一个拼接,如果他们都是1000X1维的,拼接在一起就是1000X2维的了。
双向RNN需要的内存是单向RNN的两倍,因为在同一时间点,双向RNN需要保存两个方向上的权重参数,在分类的时候,需要同时输入两个隐藏层输出的信息。
RNN的改进2:深层双向RNN
深层双向RNN 与双向RNN相比,多了几个隐藏层,因为他的想法是很多信息记一次记不下来,比如你去考研,复习考研英语的时候,背英语单词一定不会就看一次就记住了所有要考的考研单词吧,你应该也是带着先前几次背过的单词,然后选择那些背过,但不熟的内容,或者没背过的单词来背吧。





如图所示,你会发现每个cell都会有一个损失,我们已经定义好了损失函数,接下来就是熟悉的一步了,那就是根据损失函数利用SGD来求解最优参数,在CNN中使用反向传播BP算法来求解最优参数,但在RNN就要用到BPTT,它和BP算法的本质区别,也是CNN和RNN的本质区别:CNN没有记忆功能,它的输出仅依赖与输入,但RNN有记忆功能,它的输出不仅依赖与当前输入,还依赖与当前的记忆。这个记忆是序列到序列的,也就是当前时刻收到上一时刻的影响,比如股市的变化。
因此,在对参数求偏导的时候,对当前时刻求偏导,一定会涉及前一时刻。
7. 长短时记忆单元(Long-Short Term Memory,简称LSTM)
为了解决上述时间轴上的梯度发散,机器学习领域发展出了长短时记忆单元(Long-Short Term Memory,简称LSTM),通过门的开关实现时间上的记忆功能,并防止梯度发散。
LSTM(Long Short-Term Memory)长短期记忆网络,是一种时间递归神经网络,适合于处理和预测时间序列中间隔和延迟相对较长的重要事件。LSTM是解决循环神经网络RNN结构中存在的“梯度消失”问题而提出的,是一种特殊的循环神经网络。最常见的一个例子就是:当我们要预测“the clouds are in the (…)"的时候, 这种情况下,相关的信息和预测的词位置之间的间隔很小,RNN会使用先前的信息预测出词是”sky“。但是如果想要预测”I grew up in France … I speak fluent (…)”,语言模型推测下一个词可能是一种语言的名字,但是具体是什么语言,需要用到间隔很长的前文中France,在这种情况下,RNN因为“梯度消失”的问题,并不能利用间隔很长的信息,然而,LSTM在设计上明确避免了长期依赖的问题,这主要归功于LSTM精心设计的“门”结构(输入门、遗忘门和输出门)消除或者增加信息到细胞状态的能力,使得LSTM能够记住长期的信息。

标准的RNN结构都具有一种重复神经网络模块的链式形式,一般是一个tanh层进行重复的学习(如上图左边图),而在LSTM中(上图右边图),重复的模块中有四个特殊的结构。贯穿在图上方的水平线为细胞状态(cell),黄色的矩阵是学习得到的神经网络层,粉色的圆圈表示运算操作,黑色的箭头表示向量的传输,整体看来,不仅仅是h在随着时间流动,细胞状态c也在随着时间流动,细胞状态c代表着长期记忆。
上面我们提到LSTM之所以能够记住长期的信息,在于设计的“门”结构,“门”结构是一种让信息选择式通过的方法,包括一个sigmoid神经网络层和一个pointwise乘法操作,如下图所示结构。复习一下sigmoid函数, ,sigmoid输出为0到1之间的数组,一般用在二分类问题,输出值接近0代表“不允许通过”,趋向1代表“允许通过”。
在LSTM中,第一阶段是遗忘门,遗忘层决定哪些信息需要从细胞状态中被遗忘,下一阶段是输入门,输入门确定哪些新信息能够被存放到细胞状态中,最后一个阶段是输出门,输出门确定输出什么值。下面我们把LSTM就着各个门的子结构和数学表达式进行分析。



双向LSTM
双向RNN由两个普通的RNN所组成,一个正向的RNN,利用过去的信息,一个逆序的RNN,利用未来的信息,这样在时刻t,既能够使用t-1时刻的信息,又能够利用到t+1时刻的信息。一般来说,由于双向LSTM能够同时利用过去时刻和未来时刻的信息,会比单向LSTM最终的预测更加准确。下图为双向LSTM的结构。


查看全文
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.dgrt.cn/a/2281646.html
如若内容造成侵权/违法违规/事实不符,请联系一条长河网进行投诉反馈,一经查实,立即删除!
相关文章:
神经网络/深度学习
https://github.com/apachecn/AiLearning https://github.com/imhuay/Algorithm_Interview_Notes-Chinese
1. 感知机
感知机(perceptron)是由两层神经元组成的结构,输入层用于接受外界输入信号,输出层(也被称为是感知……
编程日记2023/4/11 15:37:10
FIFO,LRU,OPT置换算法
#include<iostream>#include <cstdlib>#include <ctime>#define L 20 //页面长度最大为20using namespace std;int M; //内存块struct Pro//定义一个结构体{int num,time;};Input(int m,Pro p[L])//打印页面走向状态{cout<<"请输入页面长度(10……
编程日记2023/4/11 15:37:04
单独的FIFO
#include<iostream>#include<iomanip>using namespace std;#define m 5 //m表示页数#define n 3 //n表示物理块数float interrupt0; //产生缺页中断的次数int k0; //指向最先进入内存的页,即被淘汰的页int PageTable[m]; //定义页……
编程日记2023/4/11 15:37:03
FIFO,LRU,OPT页面置换算法
#include<iostream>#include <cstdlib>#include <ctime>#define L 20 //页面长度最大为20using namespace std;int M; //内存块struct Pro//定义一个结构体{int num,time;};Input(int m,Pro p[L])//打印页面走向状态{cout<<"请输入页面长度(10……
编程日记2023/4/11 15:37:03
首次适应算法和最佳适应算法和循环首次适应算法和最坏适应算法
#include<iostream>using namespace std;int FreePartition[100];//空闲分区块数组int FirstPartition[100];//首次适应算法数组int CycleFirstPartition[100];//循环首次适应算法数组int BestPartition[100];//最佳适应算法数组int WorstPartition[100];//最坏适应算法数……
编程日记2023/4/11 15:37:02
进程调度的优先数法和简单轮转法
#include<iostream>#include<string>#include<time.h>using namespace std;int n;class PCB{public:int pri;//进程优先数int runtime;//进程运行CPU时间int pieceOftime;//轮转时间片int needOftime;//还需要时间int Counter;string procname;//进程名strin……
编程日记2023/4/11 15:37:02
服务器端用Servlet响应客户端请求,Gson请求。可以返回多个数据库中的信息
Gson解析工具类GsonUtil,可以实现对象转换为Json字符串,也可以将json字符串转换为object
package gsonutil;import java.util.ArrayList;
import java.util.List;import com.google.gson.Gson;
import com.google.gson.GsonBuilder;
import com.google.……
编程日记2023/4/11 15:37:01
Linux Apache2.2配置CGI
参考网址 http://www.thinksaas.cn/topics/0/325/325114.html CGI(公共网关接口[Common Gateway Interface])定义了网站服务器与外部内容协商程序之间交互的方法,通常是指CGI程序或者CGI脚本,是在网站上实现动态页面的最简单而常用的 方法。本文将对如何……
编程日记2023/4/11 15:37:00
linux下安装配置DBI,perl连接mysql
参考http://blog.csdn.net/stevenyanzhi/article/details/5997556
http://wenku.baidu.com/link?urlwmrhRy24SgwMt402hbkq9iXrfgVkALF-HWeoJvtbTMV_CLuTWG4H802vtHL8_JGvRMgb8kv0kmqIOmnrnhUD5RYs_BixlMBQDkeEvrjIbc7 安装DBI、Data-ShowTable、DBD-mysql (假设你已安装完per……
编程日记2023/4/11 15:37:00
【MySQL】实验九 关系代数
文章目录 1. 关系代数-检索LIU老师所授课程的课程号、课程名2. 关系代数-检索年龄大于23岁的男学生的学号和姓名3. 关系代数-检索讲授课程名为C语言的教师的姓名4. 关系代数-检索成绩在50-60之间的学生的学号和课程号5. 关系代数-检索选修课程名为C语言的学号、成绩6. 关系代数……
编程日记2023/4/11 15:37:00
python以及PyCharm工具的环境安装与配置
这里以Windows为例
Python的安装
当然是到Python官网下载咯,https://www.python.org/downloads/点我直达,如图: 可以下载最新版本,可以下拉找到之前特定的版本安装,如图: 这里先择的是最新版的进行安装……
编程日记2023/4/16 14:57:39
JavaScript【六】JavaScript中的字符串(String)
文章目录🌟前言🌟字符串(String)🌟单引号和双引号的区别🌟属性🌟 length :字符串的长度🌟 方法🌟 str.charAt(index);🌟 str.charCodeAt(index);🌟 String.fromCharCode(……
编程日记2023/4/16 14:57:29
获取文件MD5小案例(未拆分文件)
文章目录前端获取MD5后端获取MD5前端获取MD5
1、引入js
<script src"js/spark-md5.min.js" type"text/javascript"></script>注:spark-md5库GitHub链接 2、这里是一个按钮和被隐藏调的<input/>标签 <body><button……
编程日记2023/4/16 14:57:19
Java 进阶(15)线程安全集合
CopyOnWriteArrayList
线程安全的ArrayList,加强版读写分离。
写有锁,读⽆锁,读写之间不阻塞,优于读写锁。
写⼊时,先copy⼀个容器副本、再添加新元素,最后替换引⽤。
使⽤⽅式与ArrayList⽆异。
示例……
编程日记2023/4/16 14:57:08
HR:面试官最爱问的linux问题,看看你能答对多少
文章目录摘要Linux的文件系统是什么样子的?如何访问和管理文件和目录?如何在Linux中查看和管理进程?如何使用Linux命令行工具来查看系统资源使用情况?如何配置Linux系统的网络设置?如何使用Linux的cron任务调度器来执行……
编程日记2023/4/16 14:56:56
vscode开发常用的工具栏选项,查看源码技巧以及【vscode常用的快捷键】
一、开发常用的工具栏选项
1、当前打开的文件快速在左侧资源树中定位: 其实打开了当前的文件已经有在左侧资源树木定位了,只是颜色比较浅 2、打开太多文件的时候,可以关闭 3、设置查看当前类或文件的结构 OUTLINE
相当于idea 查看当前类或接……
编程日记2023/4/16 14:56:45
数据要素化条件之一:原始性
随着技术的发展,计算机不仅成为人类处理信息的工具,而且逐渐地具有自主处理数据的能力,出现了替代人工的数据智能技术。数据智能的大规模使用需要关于同一分析对象或同一问题的、来源于不同数据源的海量数据。这种数据必须是针对特定对象的记……
编程日记2023/4/16 14:56:36
【面试题 高逼格利用 类实现加法】编写代码, 实现多线程数组求和.
编写代码, 实现多线程数组求和.关键1. 数组的初始化关键2. 奇偶的相加import java.util.Random;public class Thread_2533 {public static void main(String[] args) throws InterruptedException {// 记录开始时间long start System.currentTimeMillis();// 1. 给定一个很长的……
编程日记2023/4/16 14:56:10
一个python训练
美国:28:麻省理工学院,斯坦福大学,哈佛大学,加州理工学院,芝加哥大学,普林斯顿大学,宾夕法尼亚大学,耶鲁大学,康奈尔大学,哥伦比亚大学,密歇根大学安娜堡分校,约翰霍普金斯大学,西北大学,加州大学伯克利分校,纽约大学,加州大学洛杉矶分校,杜克大学,卡内基梅隆大学,加州大学圣地……
编程日记2023/4/16 14:55:59
Mybatis03学习笔记
目录 使用注解开发
设置事务自动提交
mybatis运行原理
注解CRUD
lombok使用(偷懒神器,大神都不建议使用)
复杂查询环境(多对一)
复杂查询环境(一对多)
动态sql环境搭建
动态sql常用标签……
编程日记2023/4/16 14:55:50